이전 글인 과거 그림으로 AI 돌려보기 에서,
기존에 제가 적당히 그려두었던 스케치를 chatgpt 에게 넘겨, 이 그림이 무엇인지 sdxl 프롬프트로 알려달라 한 다음, 이를 바탕으로 로컬의 AI 그림 모델에 그려줘서 완성본을 만들었었죠.
이후에도 꽤 여러 번 비슷한 작업을 했습니다만, 바로 생각이 미치게 되는 지점이 있었죠. '이거 쉽게 자동화 될 거 같은데...'
아마 chatgpt 등의 도움을 받아 코딩으로 했다면 금방 했을 겁니다. 하지만 전 가급적 노코드 툴을 활용하여 쉬운 배포 및 확장을 하고 싶었습니다. 사실 이전부터 로컬 번역기 등을 만들어 보려고 dify 를 사용해 보고 있었는데요. 이 dify 와 comfyUI 를 연동하여 사용하는 작업을 중간에 실패하게 됩니다.
결국 저 문제를 해결하지 못해, 4월과 5월 열심히 낙서하는 동안은 모조리 수작업으로 처리하게 됩니다. 다만 꽤나 불편해서 여전히 많이 아쉬웠죠. 당시에는 그림 그리는 게 먼저라서 열심히 그리기만 했던 기억이 있네요.
그러다가 6월 와서 로컬 엔진도 ollama 에서 lmstudio로 바꾸고, 이 때 번역기도 나름 성공적으로 완성이 되면서 comfyUI 도 연동해보기 시작했고, 해법들을 찾아내면서 자동화를 완성하게 됩니다. 그렇게 해서 대충 6월 중순 쯤에 적당한 수준으로 완성하죠.
위에서 해결된 문제 중 중요한 부분이 dify 의 FILES_URL 세팅이었는데요. 관련해서는 나중에 따로 한 번 정리하도록 하겠습니다.
comfyUI workflow 구성
첨 만든 거라 좀 너저분합니다. 더불어 아직 부족한 부분들이 많습니다.
동작구조는 다음과 같습니다.
- 이미지와 현재 이미지를 무슨 타입으로 쓸 지를 입력받습니다.
- 이미지를 무슨 타입으로 쓸 지 입력받는 것은 comfyUI 의 문자열 노드를 통해서 이루어집니다. comfyUI 에서는 해당 노드에 값을 직접 입력하는 식으로 동작하지만, dify 에서는 이 부분에 변수를 집어넣게 될 겁니다.
- 문자열이 controlnet_canny, controlnet_depth 면, 이미지를 controlnet 처리쪽으로 넘깁니다.
- 이미지의 비율을 추출한 다음, 이를 1024x1024 = 1048576픽셀 개수에 가장 근접하도록 하는 가로세로를 새로이 구합니다.
- 위에서 구한 크기를 바탕으로 latent image 를 생성하고, controlnet 을 적용한 이미지를 생성합니다.
- 문자열이 image_to_image 라면, 받은 이미지를 잠재이미지로 변환합니다. 동시에 노이즈 제거양을 0.35로 세팅합니다.
다소 복잡해지게 된 데에는 이유가 좀 있는데요. 그 이유는 아래와 같습니다.
- 주어지는 문자열을 바탕으로 canny, depth, img2img 분기를 제어해야 합니다.
- canny, depth 는 controlnet 으로 합쳐 처리가 가능하지만, img2img 는 완전히 다른 구조로 처리되기에 별도의 로직을 타야 하는 문제가 있습니다.
- sdxl 의 경우 1024x1024 해상도에 최적화되어 있으므로, 주어진 스케치 이미지의 비율을 추출하여 1024x1024 픽셀 개수에 맞는 해상도를 생성 이미지의 해상도로 설정해야 할 필요가 있습니다.
부족한 부분들은 아래와 같습니다.
- 이미지 크기를 정확히 최적화하려면, 학습에 사용된 모델들에 맞는 사이즈로 맞추는 것이 좋으며, 워크플로에 사용된 WAI NSFW Illustrious 의 경우, NoobAI 등과 마찬가지로 1024x1024 이외에 768X1280, 768X1344, 832X1216, 896X1152 등의 사이즈가 최적입니다. 따라서 현재와 같이 1048576 을 비례에 맞춰 나눠 쓰는 게 아니라 저 비율에 가까운 걸 찾아서 매칭시켜 줘야 하는 게 맞습니다. 하지만 comfyUI 에서 저 조건 만드는 게 꽤 힘들어서 그냥 일단 위와 같이 구현했습니다. 코딩으로는 어려운 게 아니라서 플러그인 중에 있지 않을까 싶은데 말이죠.
- 업스케일러가 webUI 의 Hires.fix 같은 구조로 구현이 안되어 있고, face detailer 같은 것도 없다 보니, webui 와 달리 디테일이 망가지는 일이 자주 나옵니다.
주요 구동부는 그리 복잡한 구조는 아니라서 필요한 데는 수정해 쓰시면 될 듯 합니다.
참고로 워크플로우에서 사용하는 모델은 아래와 같습니다.
- 디퓨전 모델 : NAI NSFW Illustrious v14
- Controlnet Canny, Depth : NoobAIXL Controlnet
워크플로우 데이터는 아래 링크에서 받으실 수 있습니다.
다만, dify workflow 에는 이미 이 워크플로의 데이터가 들어있기 때문에, dify로 바로 쓰실 거라면 이 워크플로는 받으실 필요가 없습니다.
그리고 만약 이 워크플로 데이터를 dify에 쓰시려 한다면 이걸 그대로 쓰시지 마시고 import한 후에 export for API 로 다시 출력하시는 걸 권장드립니다.
dify workflow 작업

dify 워크플로우는 비교적 간단합니다. 정확히는 chatflow 로 시작했는데요. 그렇지 않아도 이미지 생성 시간이 긴 만큼 중간에 작업 확인을 위해서 넣어 뒀습니다.
- 먼저 사용자에게 이미지 타입값과 이미지를 받습니다.
- 이미지 타입값은 중간에 문자열 변환을 해 주는데요. 그 이유는, 선택용으로 표시되는 문자열과 comfyUI 에서 사용하는 타입 문자열을 따로 쓸 수 있게 하기 위해서입니다.
- 이미지가 있다면, llm 에게 이 이미지의 SDXL 프롬프트가 어떤 것인지 알려달라 요청합니다. 이 과정에서 realistic 과 스케치 프롬프트는 빼달라고 요청합니다. anime 체를 그리려는 거라서요. 만약 사용자가 무언가 chat text 에 입력했다면, 그 입력한 항목을 우선적으로 하여 덮어쓰도록 합니다. 예를 들어 AI 는 빨간 옷을 생각했는데, 입력값은 노란 옷이었다면, 노란 옷 우선이 되죠. 다만 temperature 값이 높다면 꼭 그렇게 되리라는 보장은 없습니다.
- 여기서 아쉬운 점이, dify 는 chatflow 에서는 기본 채팅 입력이 필수입니다. 따라서 실행시키려면 무조건 값을 아무거나 하나 입력해야 합니다. 전 그냥 . 을 입력하는데 이것도 오동작이 좀 있는 느낌이더군요.
- comfyUI workflow 문자열의 프롬프트 영역 문자열 안에, 기본적으로 필요한 프롬프트를 입력한 후, 2번의 결과값 변수를 추가해 주고, 이미지 타입값은 미리 comfyUI workflow 에 마련된 문자열 노드에 타입값으로 뽑은 변수를 추가해 줍니다.
- dify 의 comfyUI 노드는 workflow 파일을 삽입하는 게 아니라, comfyUI workflow 문자열을 그대로 박아넣게 되어 있는데, 덕분에 꽤 자유롭게 가공할 수 있다는 이점이 있습니다. 바이너리를 전달해야 하는 이미지와 같은 값이 아니라면 많은 부분을 바꿀 수 있죠. 차후에는 이걸 활용해서 좀 더 다양한 것들을 적용해 보려 합니다.
- comfyUI 를 통해 나온 이미지를 출력하면 끝.
- 1번에서 이미지가 오지 않았다면, 별도로 만들어둔 text to image 용 comfyUI workflow 로 넘어갑니다.
dify 작업 중에는 몇 가지 유의점이 있습니다.
- dify 에서 입력한 comfyUI 노드의 워크플로 필드에 들어간 문자열에서 사용하는 path 는 운영체제 의존적입니다. 이 때문에 원래 comfyUI workflow 를 export 한 곳에서 쓴 운영체제가 아니라면, 수동으로 path 분리자를 수정해 주셔야 합니다. 유닉스라면 /, 윈도라면 \ 로요. 윈도가 \ 인 이유는 \ 1개는 문자열 내의 escape 취급이라..
- 만약 단일 운영체제를 쓰신다면 이 점이 딱히 문제가 되지 않습니다만... 저의 경우 맥 스튜디오와 맥미니는 macOS, RTX4090 과 exo-v2 는 윈도 환경이다 보니, 이런 문제가 생길 수 밖에 없습니다.
- comfyUI 노드의 접속지점을 개별 노드별로 나눌 수 없습니다. 즉 comfyUI 플러그인에서 한 번 연동 접속 지점을 설정하면, 전 comfyUI 노드들의 접속 위치가 전부 바뀌게 됩니다.
일단 워크플로우는 이런 구조이구요. 각 노드에 연동되는 툴들은 다음과 같습니다. 참고로 dify 가 동작하는 환경은 M4 Mac Studio 128GB 에서 구동하는 docker입니다.
- LLM 노드
- M4 Mac Studio 128GB 에서 동작하는 LMStudio 의 openAI API 호환 연동을 사용합니다. 사용한 모델은 gemma3-27b-abliterated 입니다.
- comfyUI 노드
- RTX4090 이 달린 윈도 머신의 comfyUI 와 연동됩니다. 처음에는 M4 Mac Studio 에서 구동하는 것을 그대로 쓰려고 했습니다. 하지만 이미지 생성에서 최소 7-8배 차이가 나는 만큼 너무 느려져서 한동안은 RTX4090 으로 돌리기로 했습니다. 이 과정에서 위의 경로 분리자 문제를 겪었습니다.
사용해 보기
dify chatflow 의 서비스를 연 다음 구동해 봅니다. 아래와 같은 화면이 나타납니다. 다만 요 스샷은 이미 이미지 용도와 사용 이미지 업로드를 한 상태네요. 직접 업로드 외에 외부 URL도 사용 가능합니다.

이미지 타입을 설정하고 이미지를 업로드해 봅니다. 이미지는 이전의 링크의 것을 선택하고, 창을 닫습니다. 이렇게 하면 간략한 설명이 나오고 채팅창을 사용할 수 있는데요.
이 채팅창에 간단한 프롬프트를 입력해 봅니다.
프롬프트를 입력하면, 연결된 LLM 이 입력한 프롬프트를 고려하여 자신이 분석한 프롬프트와 잘 합쳐서 결과를 보여줍니다. 그리고 이 프롬프트를 바탕으로 이미지를 생성하기 시작하죠. 최종적으로 아래와 같이 나왔습니다.

결과가 나왔는데요. 이전 업로드 그림에 비하면 아무래도 좀 아쉽습니다.

위에 설명한대로 이건 이럴 수 밖에 없는 이유가 있습니다.
- 기본적으로 그림이 캐릭터 전신을 표현하는 그림이다보니 얼굴과 손 등에서 디테일이 날아가기 쉽습니다.
- 1번의 문제를 회피하기 위해 detailer 를 사용하여 얼굴이나 손의 디테일을 올리기도 하고, 요즘은 sdwebui 에서 hires.fix 를 1.5배로 해서 처리하는 것으로 해결하는 편인데요. 이 기능이 모두 이번에 만든 comfyUI workflow 에는 구현되어 있지 않습니다. 유일하게 R-ESRGAN x4 Anime 6B 를 활용한 업스케일만 적용되어 있는데, sdwebui 의 hires 처럼 구현하려면 이렇게 하면 안되죠.
- 스케치 자체가 너무 옅고 애매하게 표현되어 있어서 이전 수동 작업에서는 controlnet canny 의 threshold 값을 미세조정하여 잘 뽑히는 이미지가 되도록 조정을 했었고, 그림이 모호한 만큼 controlnet 가중치도 어느 정도 낮춰서 AI 쪽이 부족한 부분을 알아서 보충하는 식으로 처리하게 했었죠. 하지만 이 자동화에서는 threshold 및 가중치 값이 모두 고정값이기 때문에 이와 같은 미세조정을 할 수가 없었습니다. 그렇기에 스케치가 너무 대충인 위와 같은 그림에서는 좋은 결과가 나오기 힘들죠.
3번의 경우 원래 LLM 에게 이미지를 넘겨서 적절한 canny 가중치값도 선택해 달라고 할 예정이었습니다만, 테스트 해 보니 전혀 유용한 값을 넘겨주지 않았고, 이 때문에 이 부분은 포기하게 됩니다. 차후 버전의 워크플로에서는 canny, depth 용 Threshold 값을 별도 입력란을 통해 입력받으려 합니다.
하지만 여기서 아쉬워 하긴 이르죠. 그렇다면 깔끔한 스케치로 구성된 이미지라면 어떨까요?
올해 3-5월 사이 그렸던 그림 중에, 외곽선을 깔끔하게 따 놓은, 상반신 중심의 스케치가 하나 있었습니다. 이 스케치는 먼저 시도한 스케치의 문제점을 대부분 회피할 수 있는 이미지이죠.

그렇다면 이 스케치를 통해 나온 결과를 볼까요?
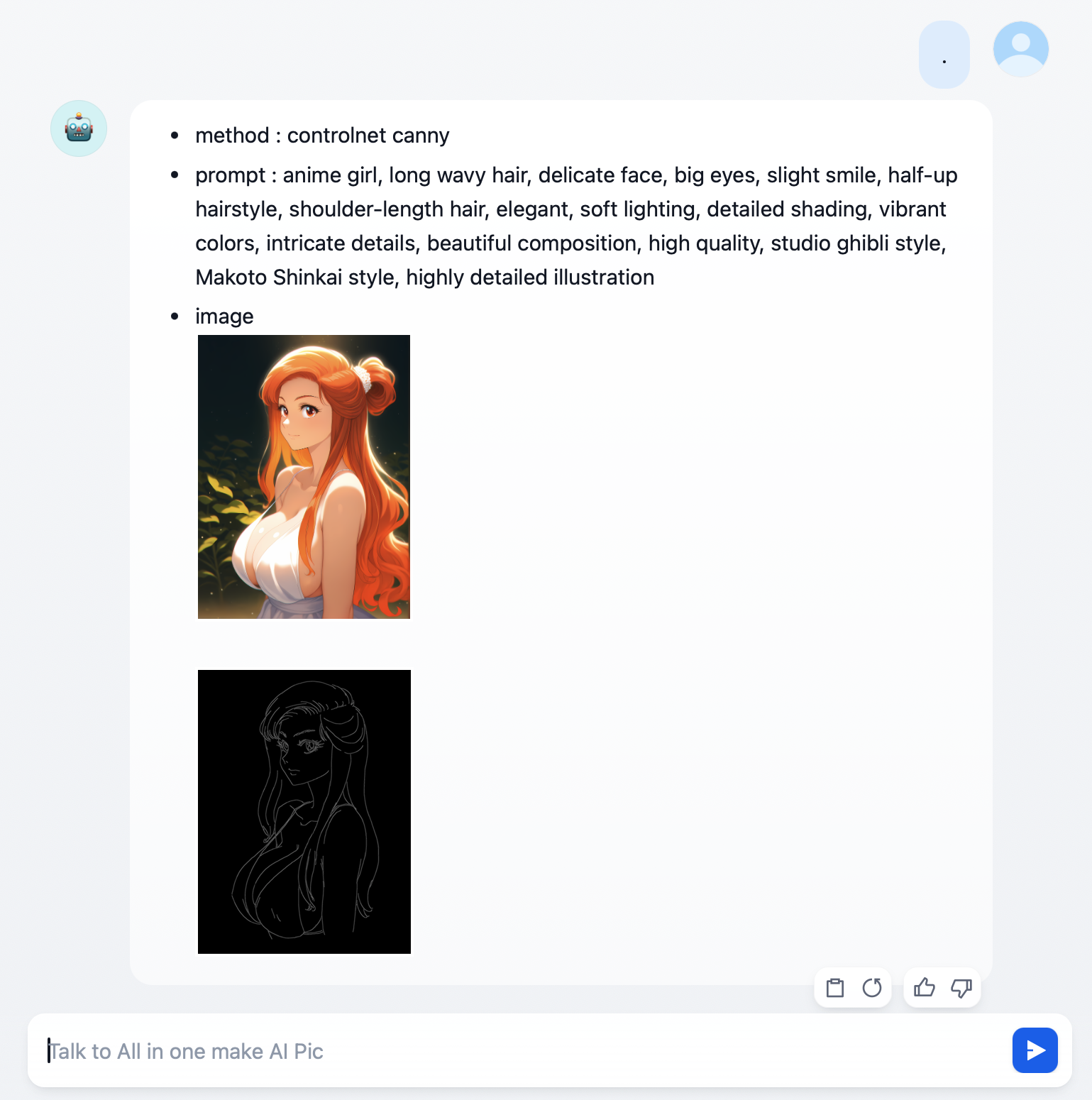
오 별도의 프롬프트를 붙이지 않아도 꽤 괜찮게 나옵니다. 사실 현재 워크플로의 목적을 생각한다면 이 정도 스케치 정도가 되어야 결과가 잘 나오는 쪽이 맞겠지만... 아무래도 좀 아쉽긴 하죠. 스케치 후작업이 길어지니...
다만 아쉬운 점이라면, 스케치 분석 통과하면서 스튜디오 지브리라거나 신카이 마코토 풍이라거나 하는 프롬프트가 붙어버렸네요. 이런 경우가 제법 있는지라 (특히 외곽선 좀 두껍게 하면 얄짤없이 알폰스 무하가 낑겨들어옵니다.) LLM 에게 이런 거 빼라고 시킨 적도 있는데, 제대로 동작하지 않아서 결국에는 넣어두지 않았습니다.

차후에는 옵션을 일일이 선택하는 것은 아닐 지라도, 대충 스케치한 것과 다듬은 것 정도의 옵션을 나눠 입력하는 정도는 제공해야 할 거 같습니다.
어쨌거나 이렇게 해서 일단 자동화 작업의 시작길은 뚫어 둔 셈이 되었습니다. 앞으로 계속 작업해서 좀 더 편하게 사용할 수 있게 고쳐봐야겠죠.
위에서 만든 워크플로는 아래 링크에서 받으실 수 있습니다.



{kind=link}